Research
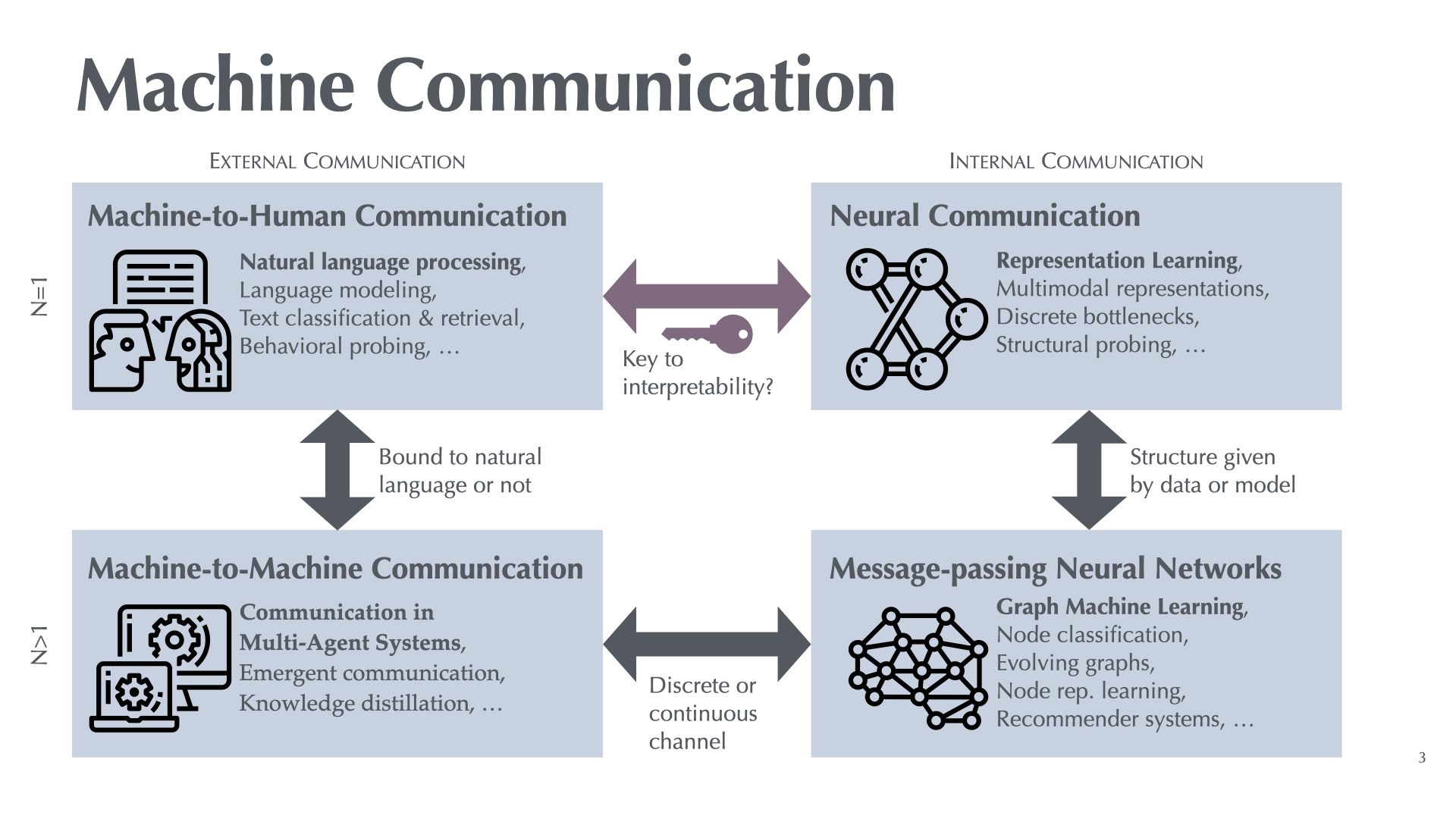
The Machine Learning x Communication Lab at the University of Southern Denmark in Odense investigates selected topics in Data Science and Advanced Machine Learning with a focus on machine communication. Our research covers four main areas:
- Machine-to-Human Communication: Machines learning to communicate with humans
- Machine-to-Machine Communication: Machines learning to communicate with each other
- Neural Communication: Transmission of information within neural networks
- Message-Passing Neural Networks: Transmission of information through a given graph
Current Focus Areas
By viewing adjacent fields Natural Language Processing, Multi-Agent Systems, Learning from Graphs, Representation Learning through the lens of machine communication, we can discover valuable new links. Specifically, our (current) focus areas are:
- The causal effects of internal communication on external communication, similar to the young research field of mechanistic interpretability.
- Continual adaptation in the non-stationary environment of communication, using techniques of lifelong machine learning
- Machine communication for data science, applying developed methods to gain insights from data, such as corpora of interlinked scholarly documents or social media postings.
Selected Publications
Lifelong Learning on Evolving Graphs Under the Constraints of Imbalanced Classes and New Classes
In Neural Networks 164, 2023
Abstract
Lifelong graph learning deals with the problem of continually adapting graph neural network (GNN) models to changes in evolving graphs. We address two critical challenges of lifelong graph learning in this work: dealing with new classes and tackling imbalanced class distributions. The combination of these two challenges is particularly relevant since newly emerging classes typically resemble only a tiny fraction of the data, adding to the already skewed class distribution. We make several contributions: First, we show that the amount of unlabeled data does not influence the results, which is an essential prerequisite for lifelong learning on a sequence of tasks. Second, we experiment with different label rates and show that our methods can perform well with only a tiny fraction of annotated nodes. Third, we propose the gDOC method to detect new classes under the constraint of having an imbalanced class distribution. The critical ingredient is a weighted binary cross-entropy loss function to account for the class imbalance. Moreover, we demonstrate combinations of gDOC with various base GNN models such as GraphSAGE, Simplified Graph Convolution, and Graph Attention Networks. Lastly, our k-neighborhood time difference measure provably normalizes the temporal changes across different graph datasets. With extensive experimentation, we find that the proposed gDOC method is consistently better than a naive adaption of DOC to graphs. Specifically, in experiments using the smallest history size, the out-of-distribution detection score of gDOC is 0.09 compared to 0.01 for DOC. Furthermore, gDOC achieves an Open-F1 score, a combined measure of in-distribution classification and out-of-distribution detection, of 0.33 compared to 0.25 of DOC (32% increase).
Bag-of-Words vs. Graph vs. Sequence in Text Classification: Questioning the Necessity of Text-Graphs and the Surprising Strength of a Wide MLP
In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022
Abstract
Graph neural networks have triggered a resurgence of graph-based text classification methods, defining today’s state of the art. We show that a wide multi-layer perceptron (MLP) using a Bag-of-Words (BoW) outperforms the recent graph-based models TextGCN and HeteGCN in an inductive text classification setting and is comparable with HyperGAT. Moreover, we fine-tune a sequence-based BERT and a lightweight DistilBERT model, which both outperform all state-of-the-art models. These results question the importance of synthetic graphs used in modern text classifiers. In terms of efficiency, DistilBERT is still twice as large as our BoW-based wide MLP, while graph-based models like TextGCN require setting up an 𝒪(N^2) graph, where N is the vocabulary plus corpus size. Finally, since Transformers need to compute 𝒪(L^2) attention weights with sequence length L, the MLP models show higher training and inference speeds on datasets with long sequences.